
What Changes When the Atomic Unit of Intelligence Is No Longer a Single LLM Call?
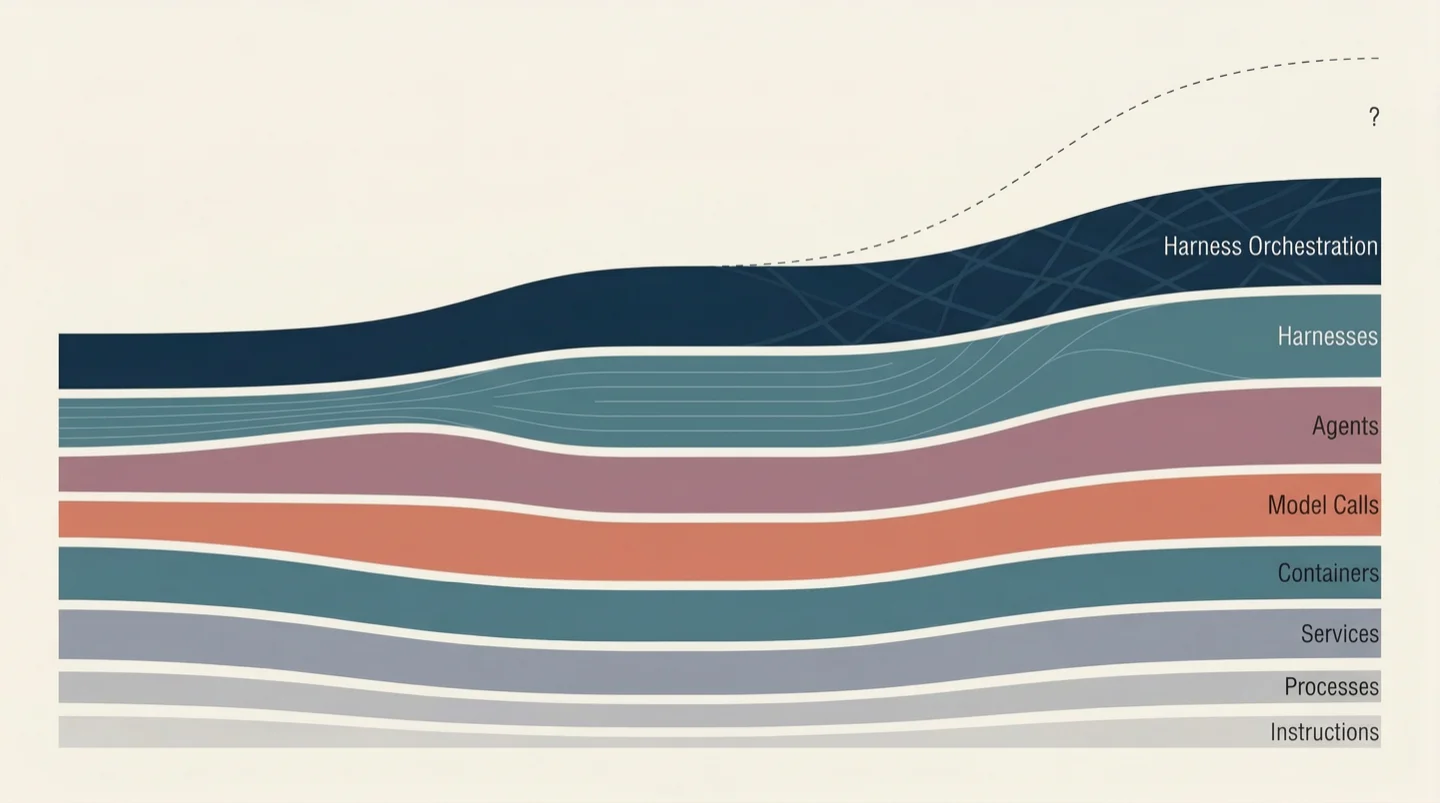
Every meaningful advance in computing has followed the same arc. A new capability appears, teams build directly on top of it, and then the unit of abstraction shifts upward. The raw capability doesn't disappear. It just stops being the thing you manage.
When computing meant individual instructions, engineers wrote assembly. When instructions got fast enough, the unit shifted to processes and threads. When processes became plentiful, the unit shifted to services. When services proliferated, it shifted to containers. At each transition, the lower layer remained intact. What changed was the contract between the layer above and the layer below. The new unit absorbed the complexity beneath it and presented a simpler interface upward. Everything built on that interface had to be rebuilt, not because the old tools were wrong, but because the problems they addressed no longer lived at the right level of abstraction.
AI is going through this transition right now, and most of the industry hasn't noticed because they're still building at the old unit.
From Calls to Harnesses
Two years ago, the atomic unit of intelligence was a model call. You sent a prompt, received a completion, parsed the output, and decided what to do next. Every orchestration framework built during this period reflected that assumption. LangChain, CrewAI, Haystack, the countless wrappers: they were tools for managing sequences of model calls, chaining prompts, routing outputs, retrying on failure, formatting responses.
Then something changed. Tools like Claude Code, Cursor, Codex, and Aider wrapped the model call inside a much larger system: a model plus tools, plus a filesystem, plus a control loop, plus memory, plus the ability to iterate, backtrack, and try a different approach when the first one fails. These systems, call them harnesses, are complete problem-solving entities with their own agency. They are not wrappers around a model. They are closer to junior engineers with perfect recall and no ego.
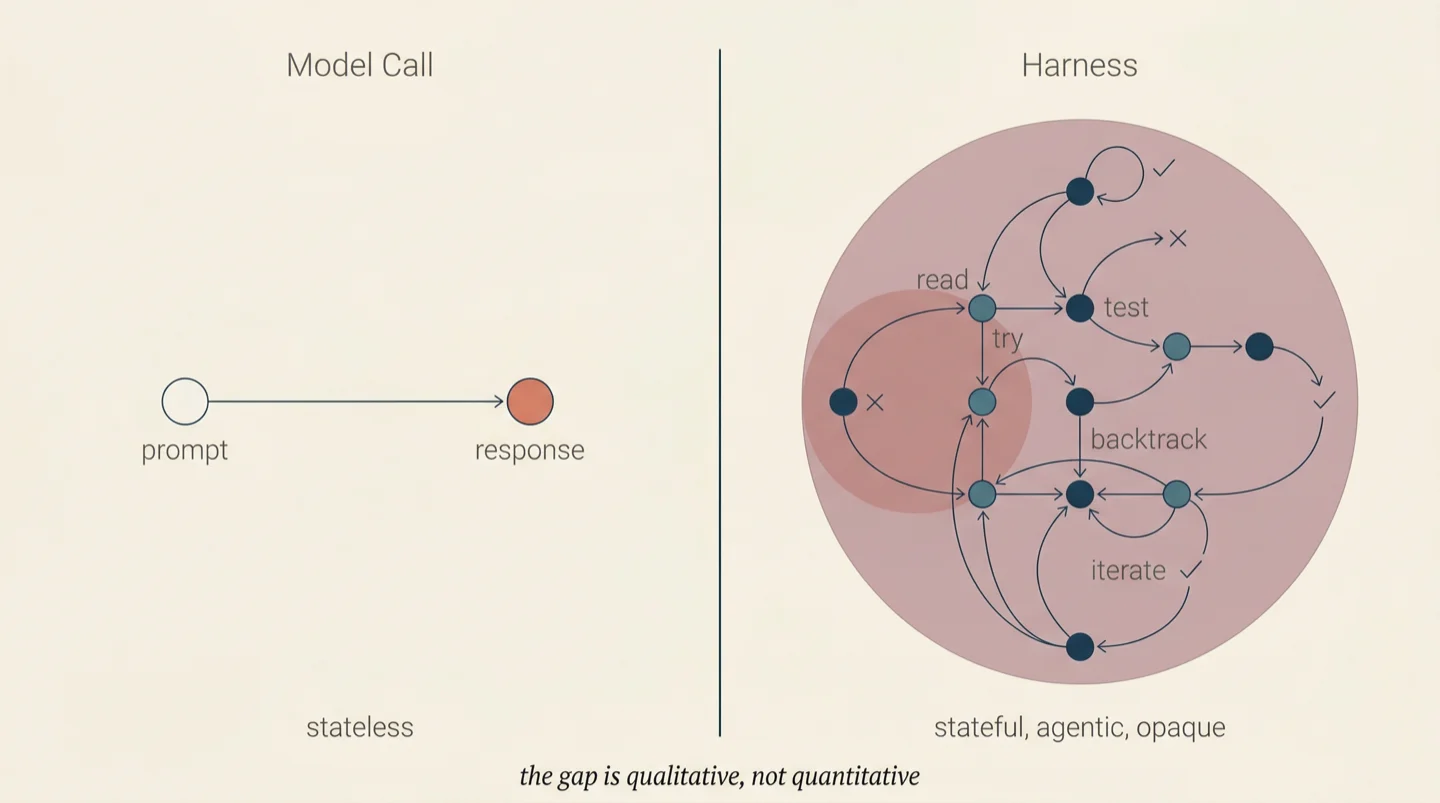
The gap between a model call and a harness is qualitative, not quantitative. A model call is stateless. You send input, you get output. The orchestrator controls every step: what to ask, when to ask it, what tools to provide, how to interpret the response. The relationship between orchestrator and model is that of a programmer and a function.
A harness is stateful, agentic, and opaque. You give it a goal, "implement JWT authentication in this codebase," and it decides what files to read, what approach to take, what tests to write, how to structure the code. It might touch three files or thirty. It might write tests first or code first. It might refactor existing code or build new modules. The orchestrator does not see these decisions happening. It sees the goal go in and the outcome come out.
Over the past year, we built an orchestration system called SWE-AF that coordinates dozens of these harnesses as specialized roles: architects, coders, reviewers, QA testers, merger agents. The system runs hundreds of agent invocations per build on real codebases, producing verified pull requests from natural language goals. Most of what follows in this essay comes from what we learned operating that system, often by getting it wrong first.
The first lesson was immediate: orchestration patterns designed for model calls do not transfer to harnesses. Prompt chains, tool-use graphs, output parsers are artifacts of the old unit. They assume the orchestrator controls the process. When the unit of intelligence has its own internal process, that assumption breaks, and everything built on it breaks with it.
The Competence-Predictability Inversion
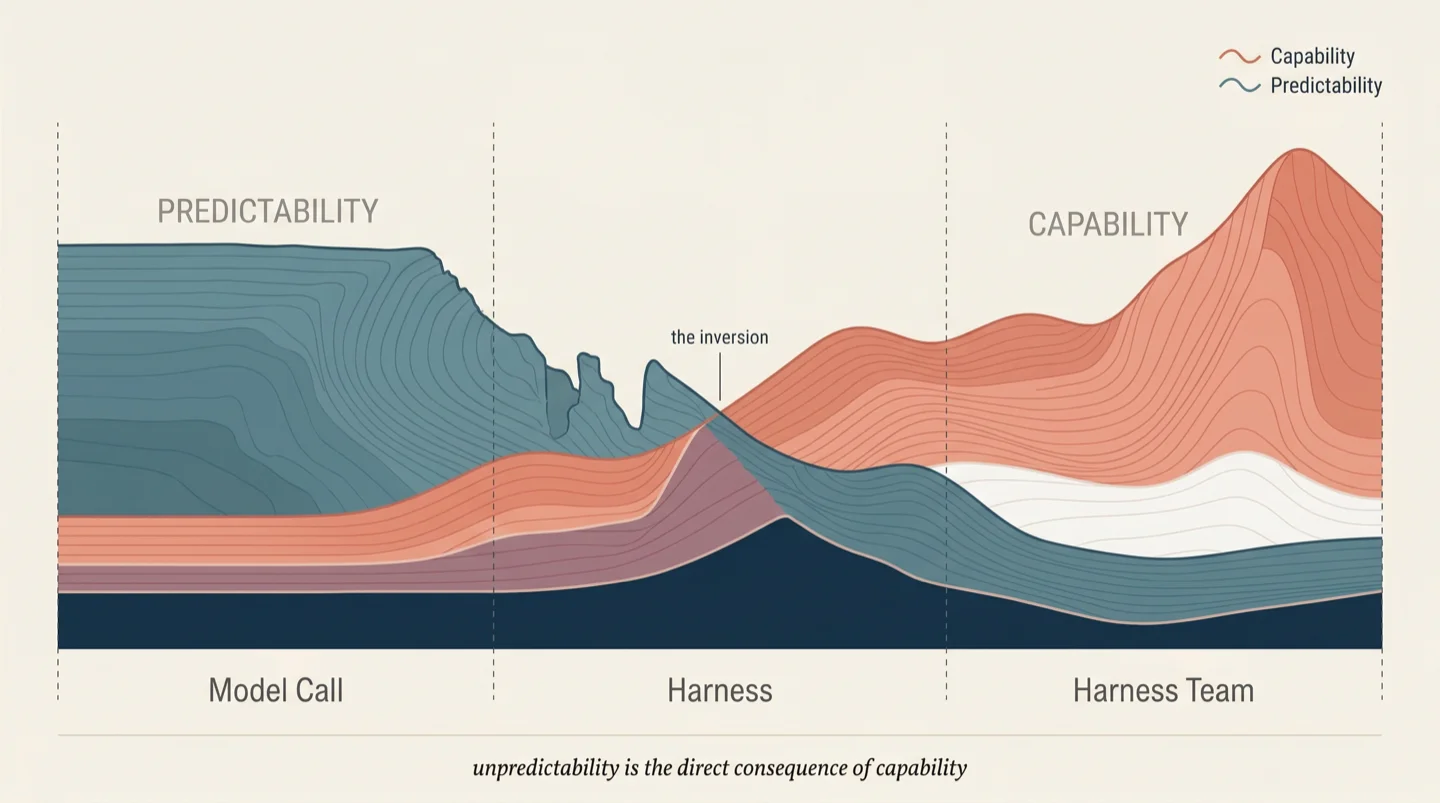
There is a relationship between the capability of the atomic unit and the predictability of its behavior, and the relationship is inverse.
A model call is highly predictable in its action space. It will produce text, structured data, or a tool call. The content varies, but the shape of the output is known. Orchestration frameworks can specify exact schemas, parse outputs with confidence, and build deterministic workflows on top of a non-deterministic component because the non-determinism is bounded.
A harness is unpredictable in its action space. Given the same goal, the same codebase, and the same model underneath, two invocations of a coding harness will read different files, make different architectural choices, write different code, run different tests, and produce different solutions. Both may be correct. Both may pass the same acceptance criteria. But the paths diverge from the first file read.
At the level of a harness team, the action space becomes combinatorially unpredictable. We see this in every SWE-AF build: ten coders working on ten issues, each making independent decisions about approach, producing code that a merger agent must reconcile into a coherent whole. No two builds follow the same execution trace, even with identical inputs. The space of possible paths is too vast.
This unpredictability is the direct consequence of capability. An entity that can adapt, backtrack, and change approach is more capable precisely because its behavior is not predetermined. Constraining a harness to follow a fixed sequence of steps reduces it to a prompt chain and gives up the capability you were paying for.
The field is responding to this by trying to make units simultaneously more capable and more predictable. That pursuit is a contradiction. The productive question runs in a different direction entirely: can you verify outcomes without controlling the process that produced them?
Engineering organizations answered this question decades ago. A VP of Engineering does not control which files an engineer edits, which variable names they use, or which design pattern they apply. They specify goals, set constraints, review outcomes, and handle escalation when teams get stuck. Engineers exercise their own judgment about approach. The manager's role is verification and governance, not process control.
From Process Control to Outcome Verification
When we first built SWE-AF, we tried the conductor approach: tightly specifying what each harness should do, in what order, with what constraints. That lasted about a week. The harnesses were capable enough to solve problems we hadn't anticipated, but only if we stopped telling them how to solve them. Micromanaging a Claude Code instance is like pair-programming with someone while dictating every keystroke. You've hired their judgment and then refused to let them use it.
The architecture we arrived at looks nothing like a prompt chain. It looks like an engineering organization.
The orchestrator defines roles, not steps. A product manager harness reads the codebase and produces a requirements document. An architect harness reads the requirements and produces a system design. A sprint planner decomposes the design into an issue DAG with dependency edges. Coders work in parallel on isolated git worktrees. QA harnesses test code they didn't write. Reviewers evaluate code they didn't write. A merger harness reconciles parallel branches using the architectural specification. Each harness has a clear responsibility and clear boundaries, but full agency within those boundaries over how the work gets done.
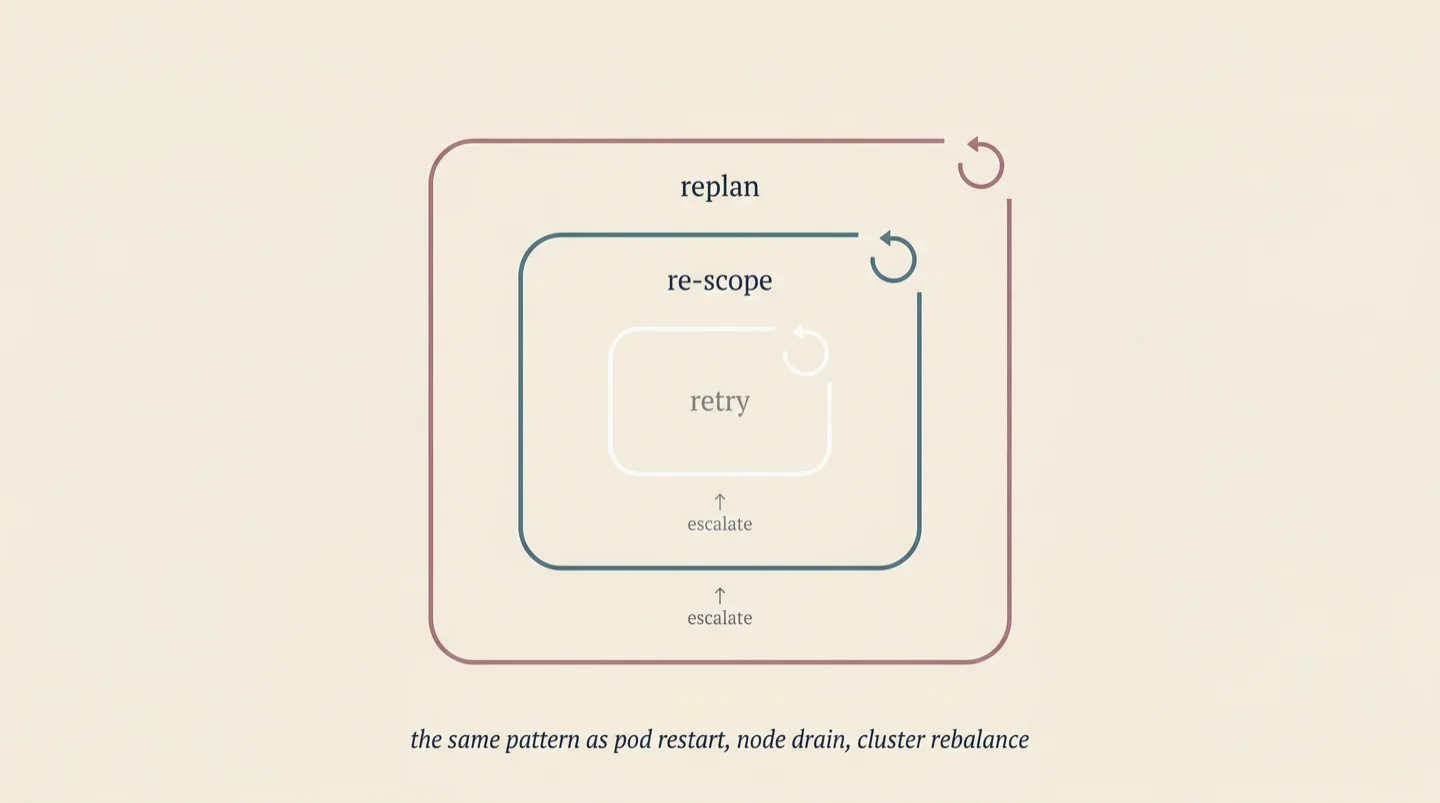
The control architecture that emerged has three nested loops, each operating at a different scope and timescale. The inner loop handles immediate failure: a coder's output doesn't pass QA, so the coder retries with the test feedback. The middle loop handles structural failure: when the inner loop exhausts its retries, an advisor harness steps in with broader context and decides whether to split the issue, change the approach, or relax the scope with explicit typed debt. The outer loop handles plan failure: when enough issues escalate, a replanner harness restructures the remaining issue DAG based on what the system has learned so far.
We did not design this architecture from first principles. We arrived at it by removing the things that didn't work, and what remained was recognizable: the same hierarchical escalation pattern that Kubernetes uses (pod restart, node drain, cluster rebalance), the same pattern that cascade controllers use in process control, the same pattern that functional engineering teams use when work turns out to be harder than estimated.
The convergence is not a coincidence. When you coordinate entities that have their own agency, whether those entities are human engineers or AI harnesses, you face the same problem: you cannot control their process, so you must verify their outcomes and govern their boundaries. The coordination patterns that solve this problem are well understood. They just haven't been applied to AI systems because, until harnesses, there was nothing to coordinate that had genuine agency.
Why the Model Fades
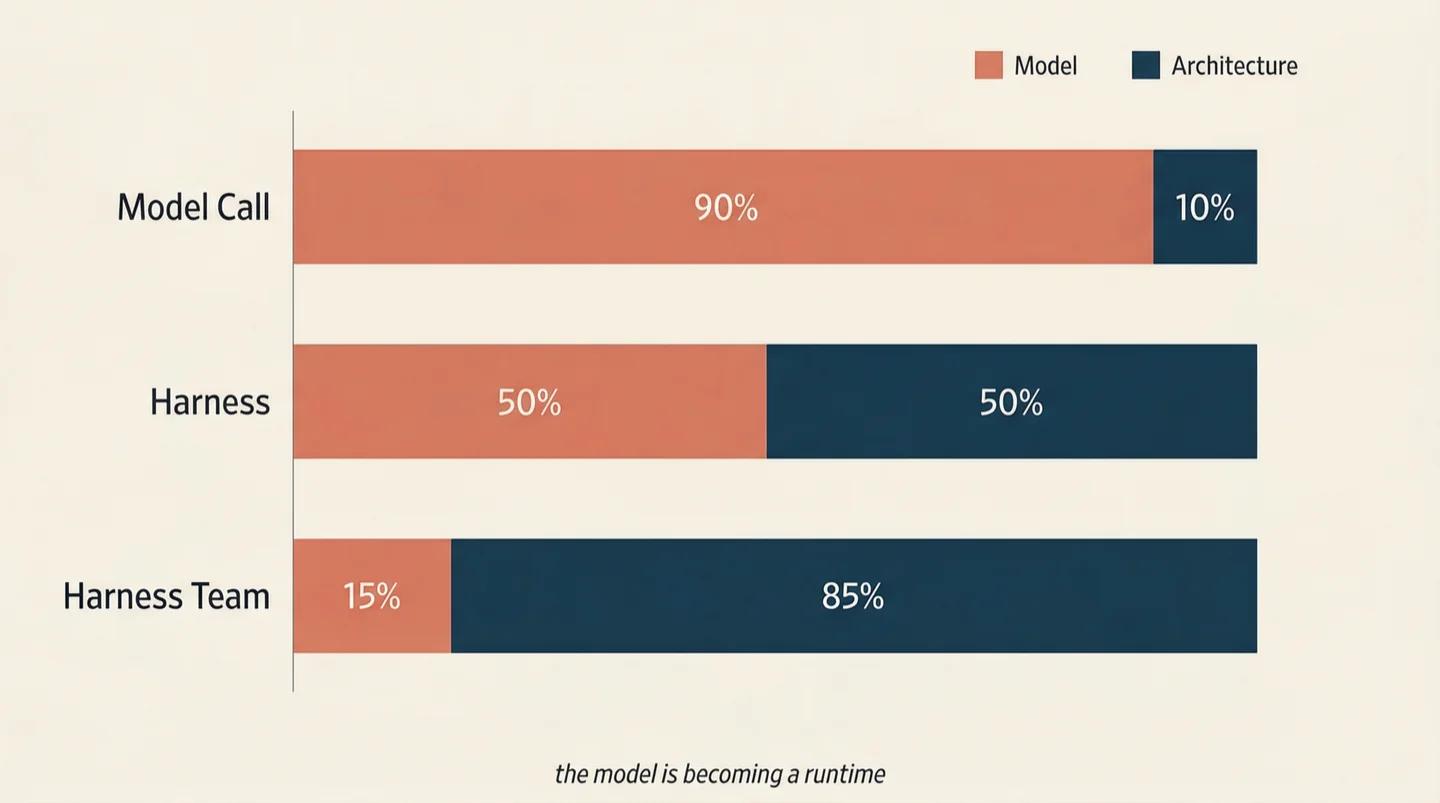
A consequence of the abstraction shift that the model-centric AI industry has no incentive to articulate: as the unit of intelligence moves up the stack, the model matters less.
At the model-call level, the model determines almost everything. The difference between a frontier model and a weaker one directly determines output quality. No system exists around the call to compensate for model weakness.
At the harness level, the model's influence narrows. The harness wraps the model in a loop: try, check, iterate. A weaker model produces worse code on the first try, but the harness's test suite catches the error, the harness reads the error message, and retries with that feedback. The process compensates for the model's limitations. The gap between a strong model and a weak one shrinks.
At the harness-team level, the model's influence shrinks further. In SWE-AF, we ran the same standardized benchmark using Claude's frontier-class haiku routing and MiniMax M2.5 at one-tenth the cost. Both scored 95 out of 100 on a rubric covering functionality, code structure, hygiene, git discipline, and quality. The models are measurably different in isolation; they produce indistinguishable results at the system level because the architecture compensates. QA catches what the coder missed. Review flags what QA didn't look for. The merger resolves conflicts using the architecture spec. Each verification layer reduces the marginal impact of model quality on the final output.
The model, in other words, is becoming a runtime. Docker abstracts away whether a container runs Python, Go, or Rust; the container's interface is the same regardless of the language inside. Harness orchestration abstracts away whether the harness runs Claude, GPT, Gemini, or an open-source model, because the architecture, not the model, determines system-level quality.
Where value accrues in the AI stack follows directly from this. If model quality is the primary driver of outcome quality, value accrues to model providers. If architecture is the primary driver, value accrues to whoever builds the orchestration infrastructure. The current industry is structured around the first assumption. The second assumption is becoming true for an increasing class of systems, and the implications are significant for anyone making long-term bets.
Verification Becomes the Product
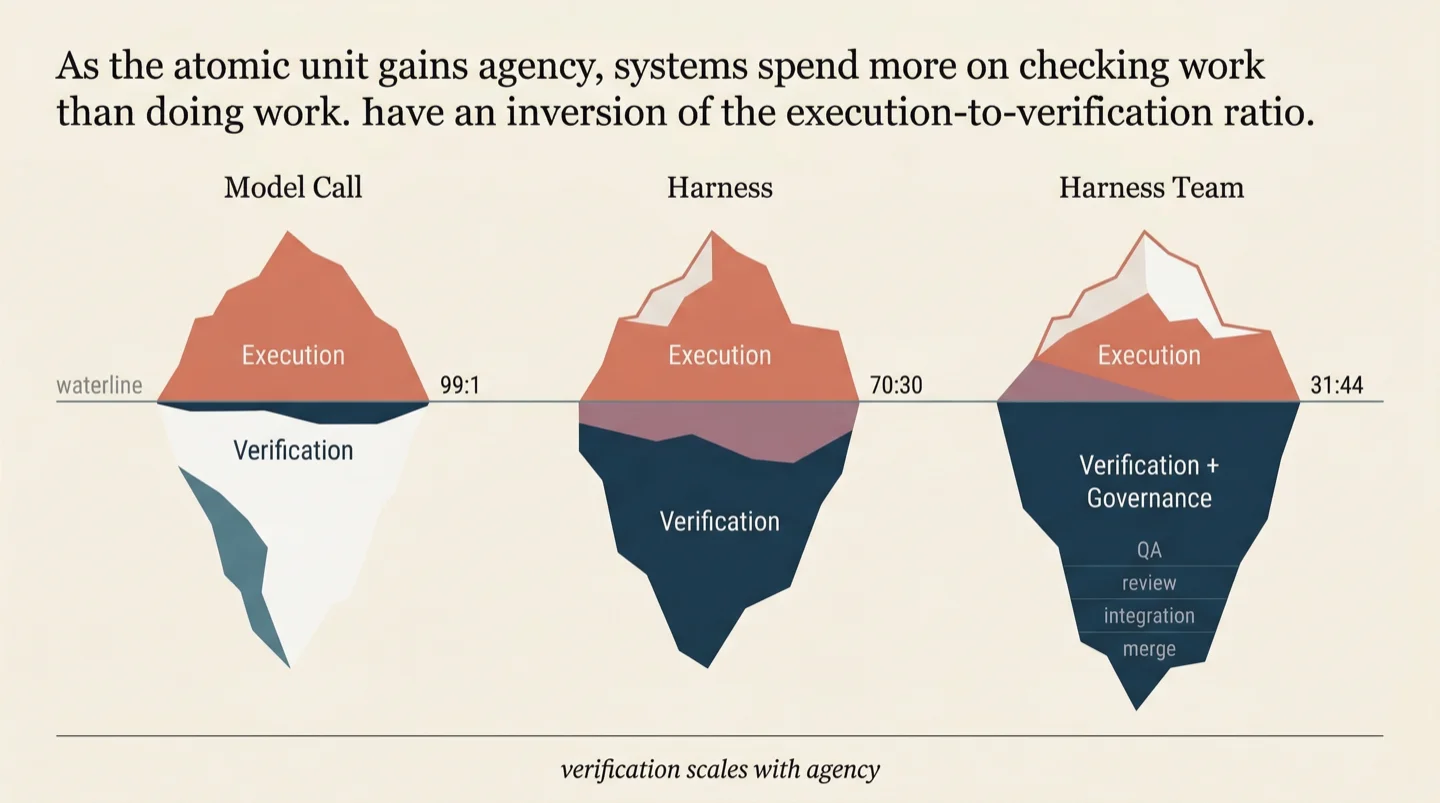
There is a ratio that shifts as you move up the abstraction stack, and it reveals where the real engineering contribution lives.
At the model-call level, nearly all computation goes to execution. You make the call, you get the output. Verification is minimal: checking that the JSON is valid, that the response isn't empty. Execution-to-verification runs roughly 99:1.
At the harness level, verification becomes significant. The harness runs tests, checks types, lints code, confirms compilation. Perhaps 70 percent of the computation is execution and 30 percent is verification. The harness's internal loop is fundamentally a cycle of try-and-verify.
At the harness-team level, the ratio inverts. In SWE-AF builds, dedicated harnesses exist solely for verification: one tests the code, another reviews it for quality and security, another tests integration across modules, another verifies the complete output against the original acceptance criteria. When we measure the actual compute cost by role, the breakdown tells the story. Coders account for about 31 percent. QA, code review, integration testing, verification, and merging account for 44 percent. The system spends more on checking work than on doing work.
Mature engineering organizations show the same pattern. A healthy software team spends more collective person-hours on code review, testing, QA, and integration verification than on writing the initial code. The pattern holds because the underlying dynamic is the same: the more capable and autonomous the units producing work, the more infrastructure you need to verify the work is sound. Verification scales with agency.
At the harness-team level, the verification architecture is what separates systems that produce reliable results from systems that produce chaos. Anyone can fire multiple AI harnesses at a problem. The differentiator is the QA agents, the review agents, the integration testers, the acceptance verifiers, the escalation paths, the typed failure propagation that tells a supervisor not just that something failed but why it failed and what kind of adaptation is appropriate. When an issue fails in SWE-AF, the failure carries a type: too complex, wrong approach, dependency missing, context overflow. The type determines the adaptation strategy. A too-complex failure triggers a split. A wrong-approach failure triggers a new attempt with different guidance. An escalation triggers a replan of the entire remaining DAG. Without typed failures, the only option is blind retry.
We have written about this before: as AI decisions scale, the infrastructure for verifying those decisions becomes more important than the infrastructure for making them. What a trillion decisions need is not a better model to make each one, but a better system to ensure the trillion decisions are collectively sound. That system is verification infrastructure, and it lives at the orchestration level.
What This Means
The abstraction shift from model calls to harnesses is already underway, and it has implications for anyone building multi-agent systems.
Orchestration patterns designed for model calls are insufficient at the harness level. Prompt chains, output parsers, and tool-routing graphs were built for a world where the orchestrator controls the process. When the atomic unit has its own agency, the orchestration layer must shift from process control to outcome verification. The primitives change: from "what prompt do I send next" to "how do I know this outcome is acceptable."
The field is over-indexed on model capability and under-indexed on control architecture. The difference between a system that reliably produces quality output and one that occasionally does is rarely the model. It is the verification loops, the escalation paths, the failure taxonomy, and the governance structure around the model. These are engineering contributions, and they are dramatically underinvested relative to their impact.
The abstraction ladder will continue to climb. Today's harness teams will become tomorrow's atomic units, orchestrated by systems operating at the level above. The same pattern took us from processes to containers to orchestrated clusters. Each level absorbs the complexity below it and presents a simpler interface upward. The organizations that invest at the right abstraction level, not the one that exists today but the one that is emerging, will build an infrastructure advantage that compounds.
The question for anyone building in this space is which unit of abstraction they are designing for. If the answer is the model call, the window for that work to matter is closing. If the answer is the harness team, the work has barely been imagined.
We have been exploring what this infrastructure looks like: from why every serious backend will need a reasoning layer, to what breaks when AI makes a trillion decisions, to why the problems CNCF solved for microservices are back, harder, for agents. The orchestration architecture described in this essay is implemented in SWE-AF, an open-source autonomous engineering runtime we built on AgentField.

Santosh Kumar Radha
Physicist & CTO at agentfield.ai — building AI infrastructure for the future.