
When LeCun's New Paper and Our Old One Landed on the Same Problem
In October 2024, we published Composite Learning Units, a framework for making LLMs learn during inference. In March 2026, Dupoux, LeCun, and Malik published Why AI Systems Don't Learn, a cognitive-science-grounded architecture for autonomous learning. The two papers share no citations and come from opposite starting points. But they converge on the same structural diagnosis and, in places, structurally similar formalisms.
In late 2024, we were working on a specific engineering problem: large language models are static at inference time. You can prompt them, retrieve context for them, chain them together, but the model itself does not change based on what it just experienced. It cannot notice a pattern across ten tasks and adjust its approach on the eleventh. Whatever was baked into the weights during training is the ceiling.
We formalized a system called Composite Learning Units (CLU) that addressed this by building a dynamic knowledge layer around a frozen model: two evolving knowledge spaces, a feedback mechanism that generates reasoning rather than scalar rewards, and a knowledge management unit that governs what to store, retrieve, and discard. The paper was published on arXiv in October 2024.
Eighteen months later, Dupoux, LeCun, and Malik published a paper approaching the same problem from the opposite direction. Instead of engineering around frozen LLMs, they started from cognitive science: how do biological organisms, especially human infants, manage to learn continuously throughout their lives? Their answer is a three-component architecture: System A for learning from observation, System B for learning from action, and System M, a meta-controller that governs when and how the other two activate.
The fields, motivations, and formalisms are different. But the structural overlap is specific enough to be worth examining carefully.
The Shared Diagnosis
Both papers begin from the same observation, stated in almost interchangeable language.
LeCun et al.: "AI models, once deployed, learn essentially nothing; their mode of operation is fixed."
Our CLU paper: models are "limited by their static nature during inference, where they rely on pre-learned knowledge without adapting to new or changing inputs."
The observation itself is not novel. The interesting part is the specific architectural requirements both papers independently derive from it.
Convergence 1: Dual Knowledge Systems
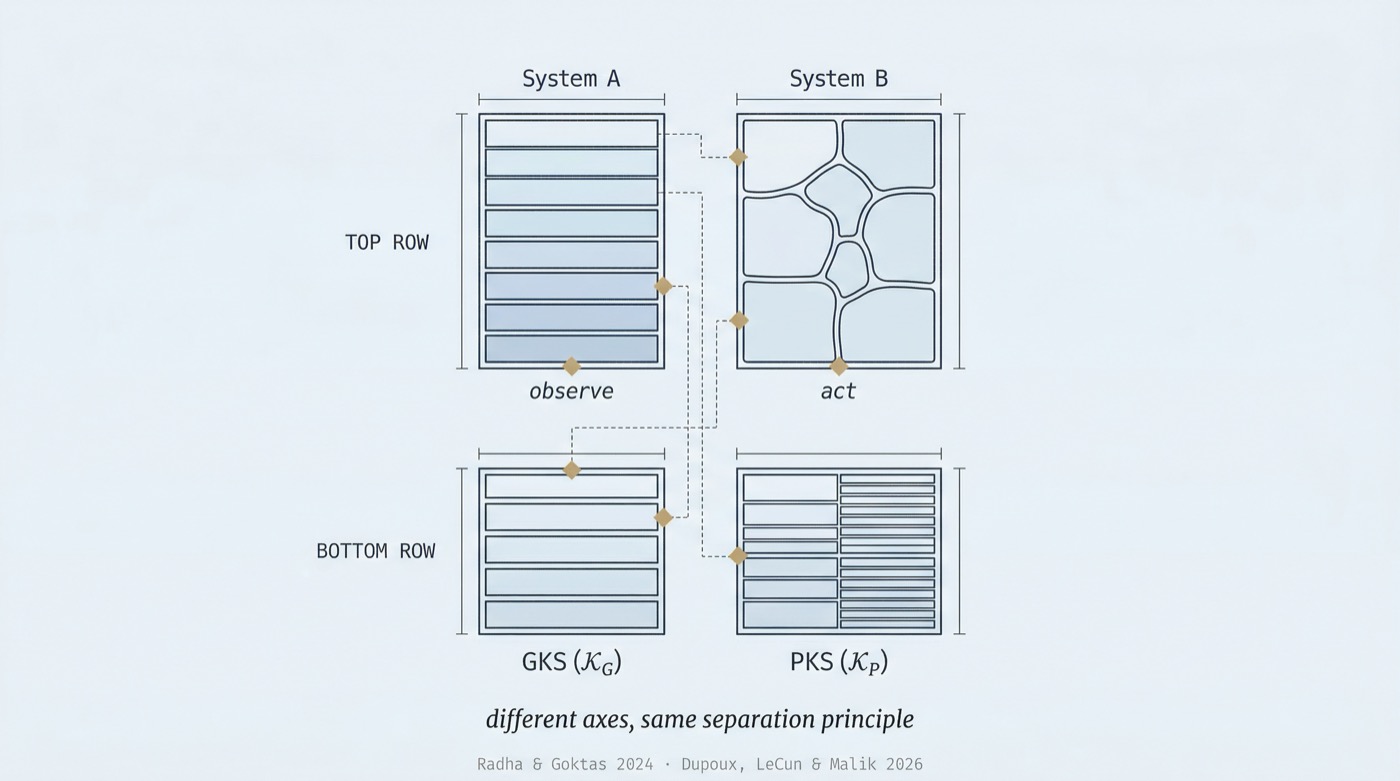
Both papers propose two distinct systems with different update dynamics rather than a single monolithic learner.
LeCun et al. separate System A (learning from passive observation, building statistical world models) from System B (learning from active interaction, optimizing behavior through trial and feedback). These are distinct learning mechanisms: they operate on different data, learn different representations, and serve different downstream purposes.
CLU separates a General Knowledge Space (𝒦_G) from a Prompt-Specific Knowledge Space (𝒦_P). These are distinct knowledge repositories: the GKS accumulates broad domain insights that generalize across tasks, while the PKS stores task-specific patterns that tune how the system prompts itself for a particular problem.
The nature of the separation differs. LeCun proposes two learning processes split by modality (observe vs. act). CLU proposes two knowledge stores split by scope (general vs. task-specific). But the underlying principle is the same: a single undifferentiated system that handles all knowledge or all learning in one place will underperform one that separates by function.
The engineering analogy is straightforward: application configuration and user session data do not belong in the same database table with the same TTL. Knowledge management has the same separation concerns.
Convergence 2: Richer-Than-Scalar Feedback
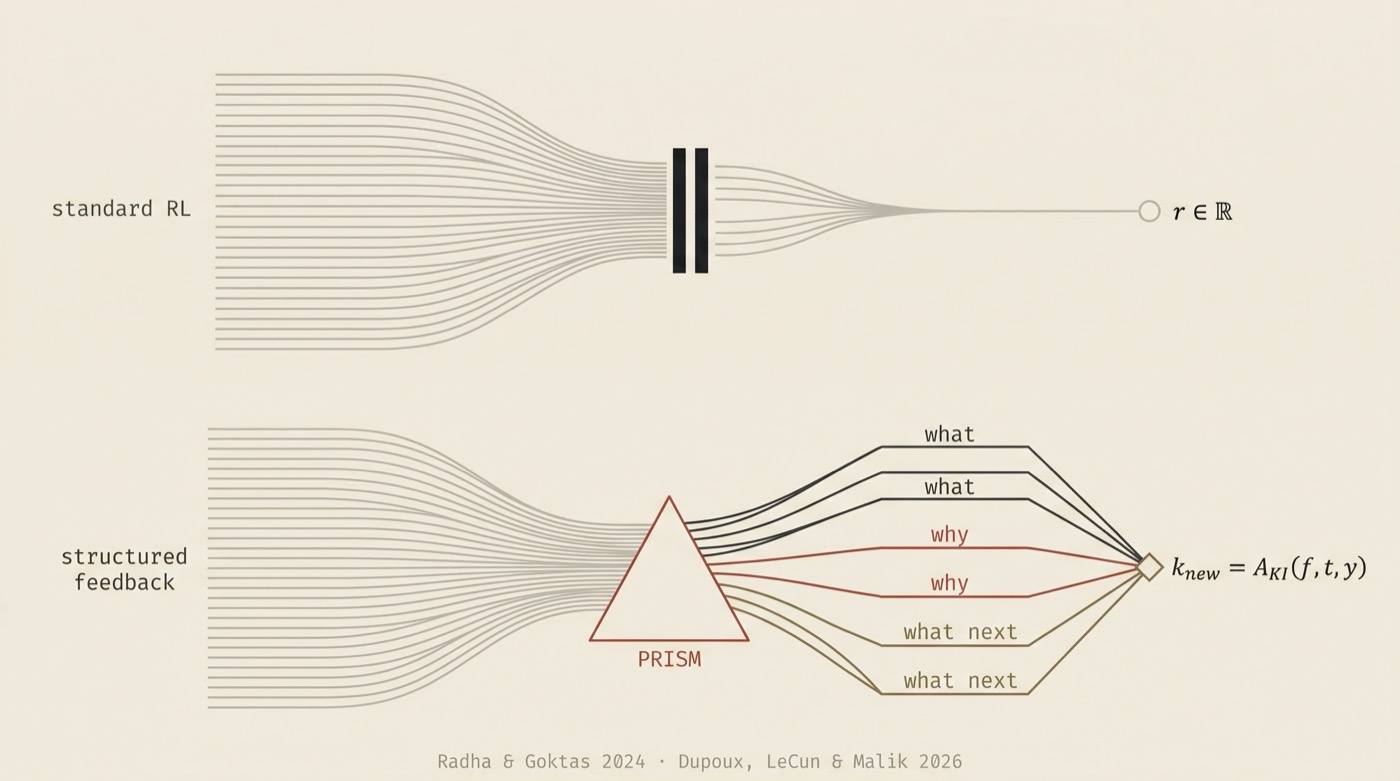
Standard reinforcement learning optimizes against a reward signal: a single number indicating how good an outcome was. Both papers, for different reasons, argue that standard reward signals are insufficient for the kind of learning they propose.
LeCun et al. note that RL is "notoriously sample-inefficient" and "depends on having well-specified reward functions," which are "rarely available in naturalistic settings." Their solution is to enrich the learning signal through world models, prediction errors, and intrinsic curiosity, so the system builds a model of environment dynamics rather than relying on sparse external rewards.
CLU takes a different path to the same destination. When the system produces an output, a comparison agent evaluates it against the expected result, producing a feedback signal c. That signal routes through one of two specialized agents:
f = A_PF(c, y, t) if c ∈ 𝒞_success
f = A_NF(c, y, t) if c ∈ 𝒞_failure
The positive feedback agent (A_PF) generates explicit reasoning about what worked and why, reinforcing successful patterns. The negative feedback agent (A_NF) generates reasoning about what failed and why, identifying specific error modes. A Knowledge Insight Agent then distills this into storable knowledge: k_new = A_KI(f, t, y).
The key distinction from RL, which we stated explicitly in the paper: "Unlike rewards in RL, which provide only a final reward signal and are challenging to design precisely due to their abstract nature, the feedback in CLU conveys reasoning about successes and failures, thereby adding explicit knowledge rather than abstract signals."
LeCun's biological evidence supports this direction from the other side: infant learning is driven by prediction errors, surprise, and the structured mismatch between expectation and observation, signals far richer than any scalar summary could provide.
The papers arrive at the same conclusion from different angles: CLU argues explicitly that scalar rewards lack explanatory content, while LeCun argues that well-specified rewards are rarely available in naturalistic settings. Both conclude that adaptive systems need learning signals richer than a single number.
Convergence 3: Meta-Control Over Learning

Both architectures include a component whose job is not to learn but to govern learning. The implementations differ substantially, but the principle that meta-control is necessary appears independently in both.
LeCun et al. call it System M. It reads internal meta-states (uncertainty, prediction error, novelty, energy levels) and outputs meta-actions: switching between observation and action modes, toggling exploration vs. exploitation, gating sensory input during sleep, routing memories for consolidation. Formally: π(aᵐ|sᵐ) maps meta-states to meta-actions. System M is a mode controller; it decides which learning system is active and how the system's resources are allocated.
CLU's Knowledge Management Unit addresses a different aspect of the same need. Rather than controlling learning modes, it governs knowledge content: what incoming knowledge to align and store, what to retrieve for a given task, and critically, what to prune. The pruning mechanism, 𝒦_G = P_G(𝒦_G, ℱⁿ), removes knowledge that accumulated feedback has revealed to be outdated or misleading. This is particularly important during early learning when the system, like a randomly initialized neural network, generates a lot of noise before it generates signal.
System M and the KMU are not doing the same thing. One controls when and how to learn; the other controls what knowledge to keep. But the shared insight is that learning without curation degrades performance. A system that absorbs everything indiscriminately will drown in stale or contradictory information. LeCun's biological evidence supports this: critical periods gate what can be learned at each developmental stage, and sleep consolidation selectively strengthens and reorganizes memories. CLU's pruning mechanism addresses the same principle through a different operation, removing bad knowledge rather than reorganizing good knowledge, but the architectural commitment is the same: something must govern the learning itself.
Convergence 4: Active Inference
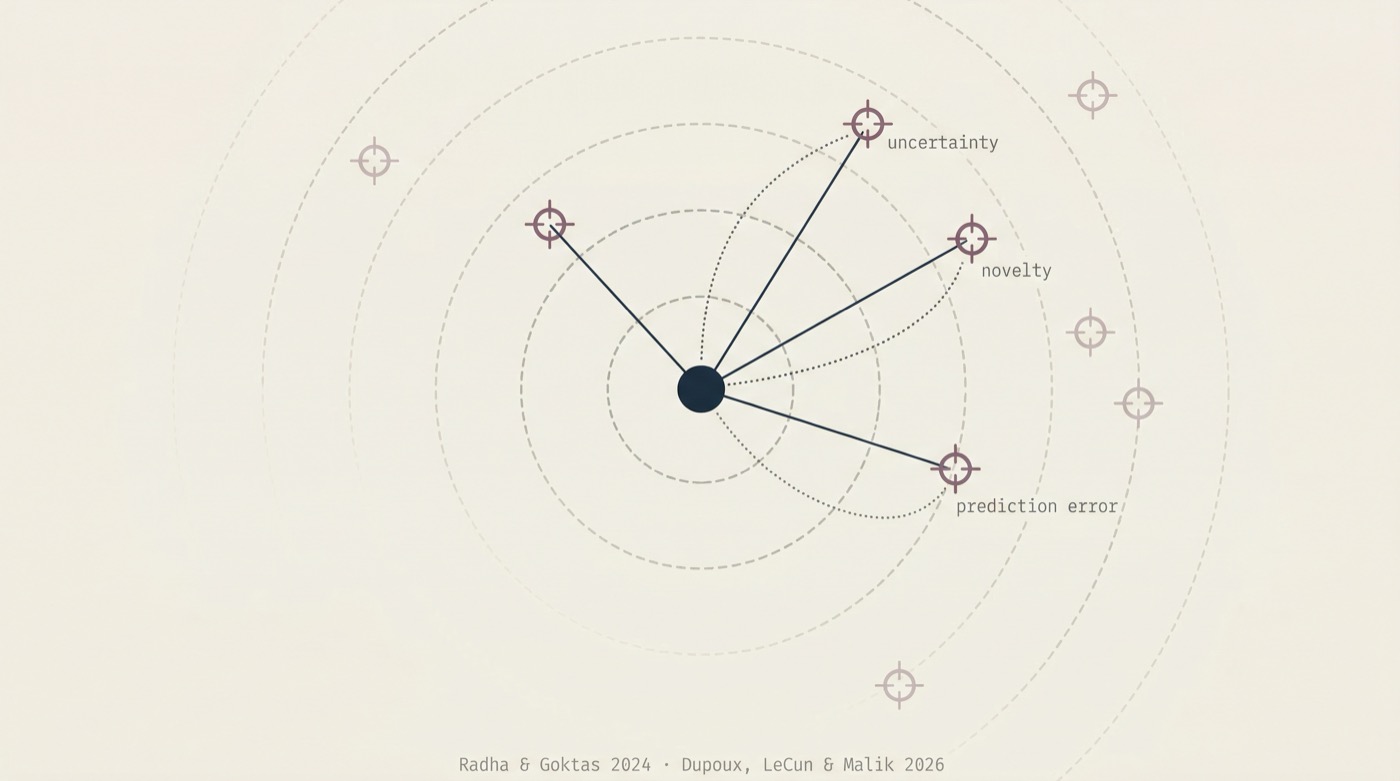
Both papers argue that adaptive systems must actively seek information rather than passively receive it, though they frame this commitment differently.
LeCun et al. ground this in embodied exploration and what they call "active perception": "We see in order to move and we move in order to see." System B physically interacts with environments, generating data that System A could never acquire through passive observation alone. The agent chooses actions not just to achieve goals but to learn about the world.
CLU arrives at the same commitment from a theoretical direction, listing active inference (the formal framework from cognitive science in which agents proactively seek information to reduce uncertainty) as one of three foundational principles. The system does not simply process inputs; it actively constructs understanding through repeated, goal-driven interaction with tasks, using feedback to guide where it directs attention next.
The framing differs. LeCun invokes active exploration as a property of embodied agents. CLU invokes active inference as a named theoretical commitment for a text-based reasoning system. But both reject the default assumption that a learning system sits passively and waits for data. When two very different architectures independently arrive at the principle that the learner must be an active participant in its own learning, it likely reflects something fundamental about what adaptation requires.
The Fundamental Divergence
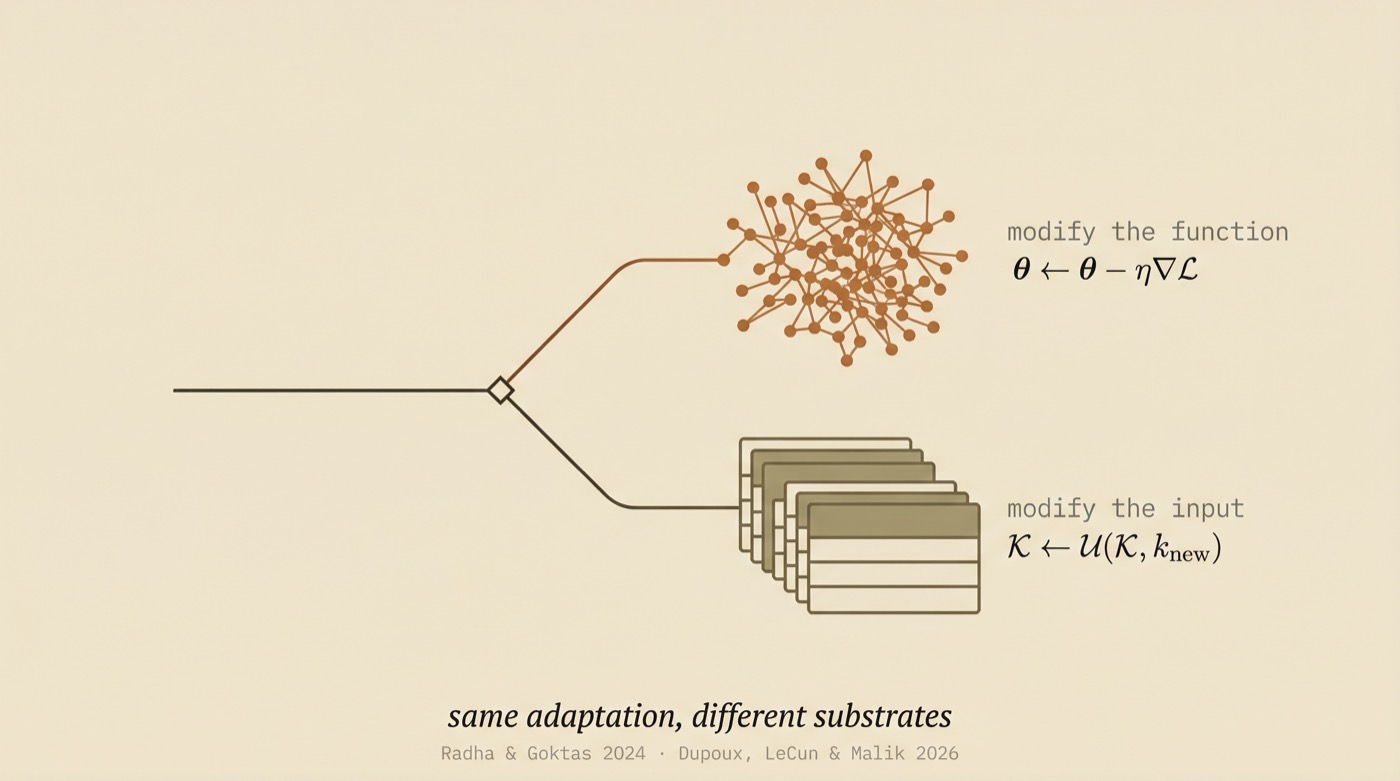
The deepest difference between the two approaches is where knowledge lives.
LeCun et al. follow the biological path: knowledge is encoded in parameters, updated through gradient-like mechanisms, evolving across what they frame as developmental and evolutionary timescales. The outer loop optimizes the "genetic code" φ that determines what the agent is capable of learning. The inner loop is a single lifetime of learning. This is ambitious, biologically grounded, and computationally demanding.
CLU makes the opposite bet. The model parameters stay frozen. All adaptation happens in external knowledge spaces. The system optimizes what it knows (the contents of 𝒦_G and 𝒦_P), not what it is (the model weights). The LLM is treated as a fixed reasoning engine that behaves differently depending on the knowledge it is given.

For software engineers, this distinction maps to a familiar tradeoff. Modifying the function is like rewriting the code; it can change fundamental behavior but is slow and risky. Modifying the input is like changing the configuration; it is fast, reversible, and safe, but bounded by what the existing code can do.
Neither approach is wrong. They are likely complementary layers in what will eventually become a full stack of adaptation: parameters for deep structural learning that reshapes what the system can do, external memory for fast contextual adaptation that reshapes what the system knows, and meta-controllers to govern when each mechanism fires.
What the Convergence Suggests
When two independent research efforts, one beginning from how infants learn to walk and the other from how language models can adapt at inference time, converge on the same four requirements (separated knowledge stores, rich feedback, meta-control over learning, and active information seeking), it suggests these are not arbitrary design choices. They may be necessary properties of any system that learns after deployment.
We are not claiming the two papers say the same thing. They do not. LeCun et al. are proposing a long-term blueprint for building fundamentally new AI architectures grounded in biology. CLU is an engineering framework for making current LLMs adaptive without retraining. The scope, mechanism, and ambition differ substantially.
But the convergence in what they identify as necessary is the interesting part. It suggests that the frozen intelligence problem has a specific shape, and that shape constrains the solution space more tightly than you might expect. If you are building systems that need to adapt, whether that is a single agent improving at a task or a fleet of agents coordinating on a codebase, these four properties are likely load-bearing requirements, not optional features.
The systems we are all building right now are frozen, and the question is how long that remains acceptable.

Santosh Kumar Radha
Physicist & CTO at agentfield.ai — building AI infrastructure for the future.