Toward a Theory of Human-Agent Experience
The absent discipline

Human-Computer Interaction has had four decades of formal study, User Experience twenty-five years as a design practice, and mobile interaction design fifteen years to develop gesture vocabularies, responsive frameworks, and the foundational insight that a phone is a device used in motion with divided attention. In each case, a body of theory emerged alongside the products themselves, giving designers a shared language for the structural properties of the interaction: Fitts's Law for pointing and selection, information architecture for navigating large content spaces, touch target sizing and reachability maps for screens held in one hand. That shared language is what allowed the field to mature; it made it possible to reason about design tradeoffs across products, across companies, across the entire discipline, rather than reinventing the foundations with every new release.
Human-Agent Experience has had no comparable development. We are three to four years into an interaction paradigm that now touches billions of people, and the field has produced no shared vocabulary for what makes one AI engagement structurally different from another, no theory that explains why a given interface feels appropriate for one kind of AI work and entirely wrong for another. The consequence of this absence is visible on every screen: the industry has converged on a single borrowed metaphor regardless of context. Consumer AI assistants, enterprise analytics platforms, developer copilots, medical triage systems, research agents that run for days and make consequential decisions along the way; the first product version is, almost without exception, a chatbot. The structural variation across these interactions is enormous, as different as a phone call is from a magazine subscription, and yet the design treatment remains identical.
Building AI systems at agentfield.ai, where a single platform must support interactions ranging from five-second factual lookups to month-long autonomous workflows carrying real-world consequences, the absence of that framework surfaces as a daily design problem rather than an abstract one. How much autonomous judgment should the system exercise before surfacing a decision to the human, and how does the answer change as trust develops over time? What level of stakes demands what kind of oversight, and is the answer different when the harm is financial versus reputational versus emotional? How does the relationship between a person and an AI agent evolve across weeks or months of collaboration, and how should the interface acknowledge that evolution rather than treating every session as a fresh encounter? These are the central design questions of this generation of software, and at the moment, each product team is answering them from scratch.
Every previous interaction paradigm eventually developed a body of design theory, and those theories shaped not only the products but the cognition and behavior of the people who used them. The desktop metaphor reshaped how people thought about organizing information; the feed redefined how they consumed media; the notification restructured how they allocated attention. These theories emerged from deliberate study of the interaction itself, and they shaped what felt possible and what felt natural long before the products reached their mature forms.
Human-Agent Experience will be no different in its consequences, only in its novelty. It will shape how people relate to systems that exercise judgment on their behalf, systems that interpret ambiguous instructions, make tradeoffs their users did not anticipate, and take actions with real and sometimes irreversible consequences. Whether that relationship is well-designed depends on whether the field develops a theoretical foundation deliberately or discovers one in hindsight, after the patterns have already calcified into defaults that billions of people mistake for inevitabilities.
This series is an attempt at the former: a first-principles inquiry into the structural properties of human-AI interaction, and a map of the design space they define.
Searching for the structural dimensions
If human-AI interactions differ structurally, the first question is what the axes of difference actually are. The natural instinct is to list the observable properties that seem to vary across interactions and treat each one as a candidate dimension of the space. Four properties surface almost immediately: temporal structure (whether the interaction unfolds in seconds, hours, or months), intent clarity (whether the human knows precisely what they want or is still figuring it out), attention requirement (how closely the human needs to watch), and output nature (whether the AI is producing an artifact, taking an action, generating an insight, or maintaining an ongoing state). Four dimensions, each with its own internal spectrum. Enough to describe the space.
But description is not theory, and the difference matters. A useful description lets you categorize an interaction after the fact; a theory lets you predict what a given region of the space demands from a design, before you build it. That predictive power depends entirely on the dimensions being genuinely independent, each one telling you something that the others cannot. If two dimensions are correlated so tightly that knowing one reliably predicts the other, you have redundancy dressed as complexity, and the framework will mislead more than it guides.
The test for independence is straightforward: for each pair of dimensions, ask whether they can vary independently. A long-running interaction with perfectly clear intent is entirely possible (a well-specified computation that runs for days), as is a brief interaction with entirely unclear intent (a quick exploratory brainstorm). Temporal structure and intent clarity pass the independence test; the correlation between them is empirical, a tendency that reflects how people happen to use current products, not a structural constraint on what is possible.
The more revealing pairing is intent clarity with attention requirement. Exploratory intent, where the human does not yet know what they want, appears to demand continuous attention almost by definition; you cannot meaningfully explore asynchronously, because the value of exploration lies in the real-time interplay between what the AI surfaces and what the human recognizes as interesting. That constraint suggests these two dimensions are not fully independent, that certain regions of the four-dimensional space may simply be unoccupiable.
But there is something more fundamental here. Attention requirement, examined closely, decomposes. A user monitors an AI closely when they do not yet trust it, when the stakes of the interaction are high, or when the task is underspecified and requires real-time steering. Remove those conditions, grant trust, lower the stakes, clarify the intent, and attention falls away on its own. Attention is not a property of the interaction at all, but a symptom of other properties, a behavioral consequence that emerges from the combination of trust, intent clarity, and stakes rather than existing as an independent dimension in its own right.
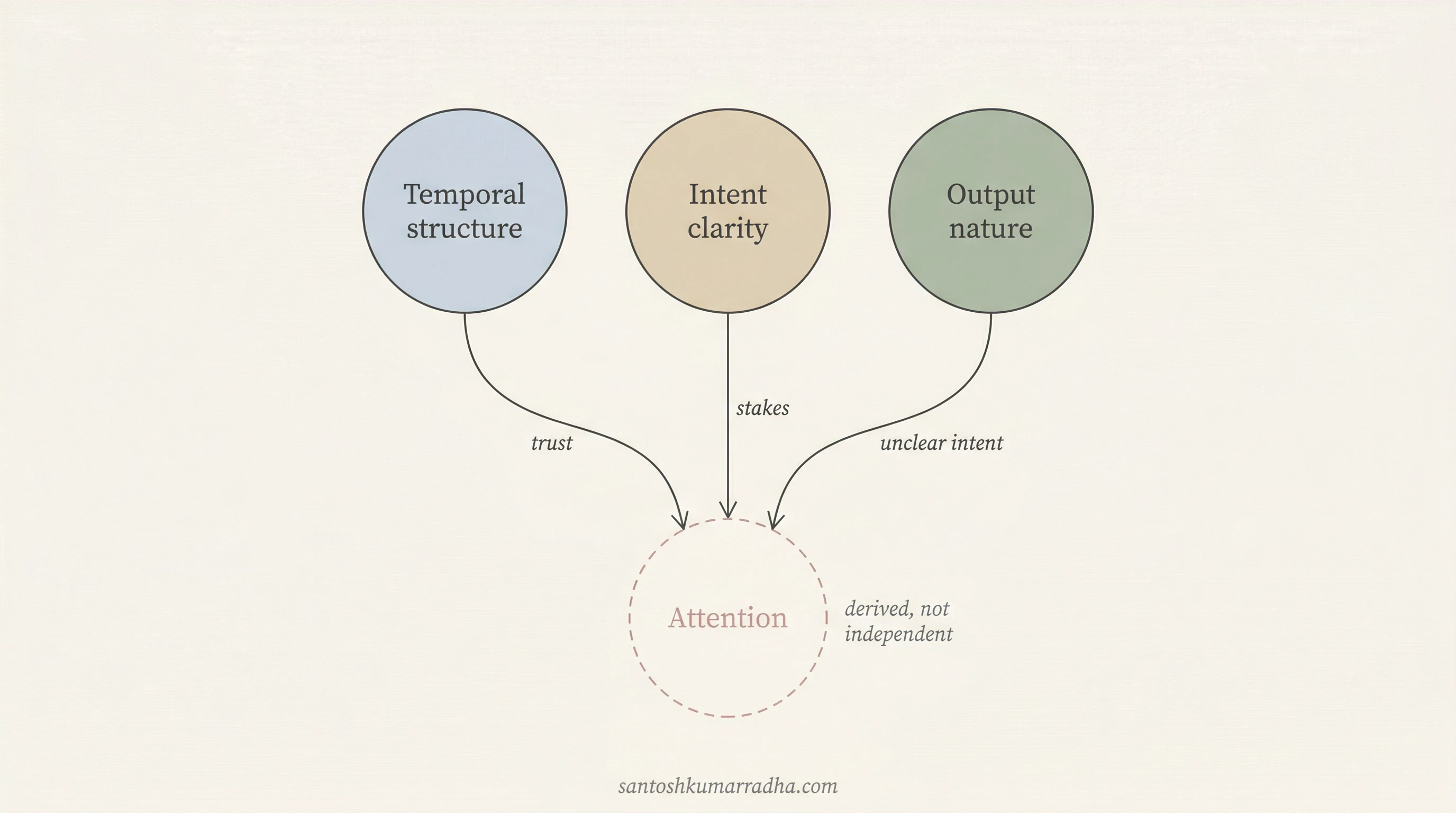
The reverse framing, that attention is the fundamental quantity and trust is derived, does not survive the same scrutiny. Trust varies independently in ways that attention does not; two people with identical attention patterns can have very different levels of trust in the system, while two people with identical trust levels in identical interaction contexts reliably converge on the same attention behavior. Attention is the dependent variable, not trust.
This compression, from four dimensions to a framework where attention is generated rather than specified, is the kind of move that distinguishes a taxonomy from a theory. The question is whether the remaining dimensions can be compressed further, and whether the right number is three, or two, or something else entirely.
Points, trajectories, and the search for stability
A separate question reshapes the entire framework. In a space defined by these dimensions, is a given AI engagement a point, sitting at fixed coordinates, or is it a trajectory, a path that moves through the space over time?
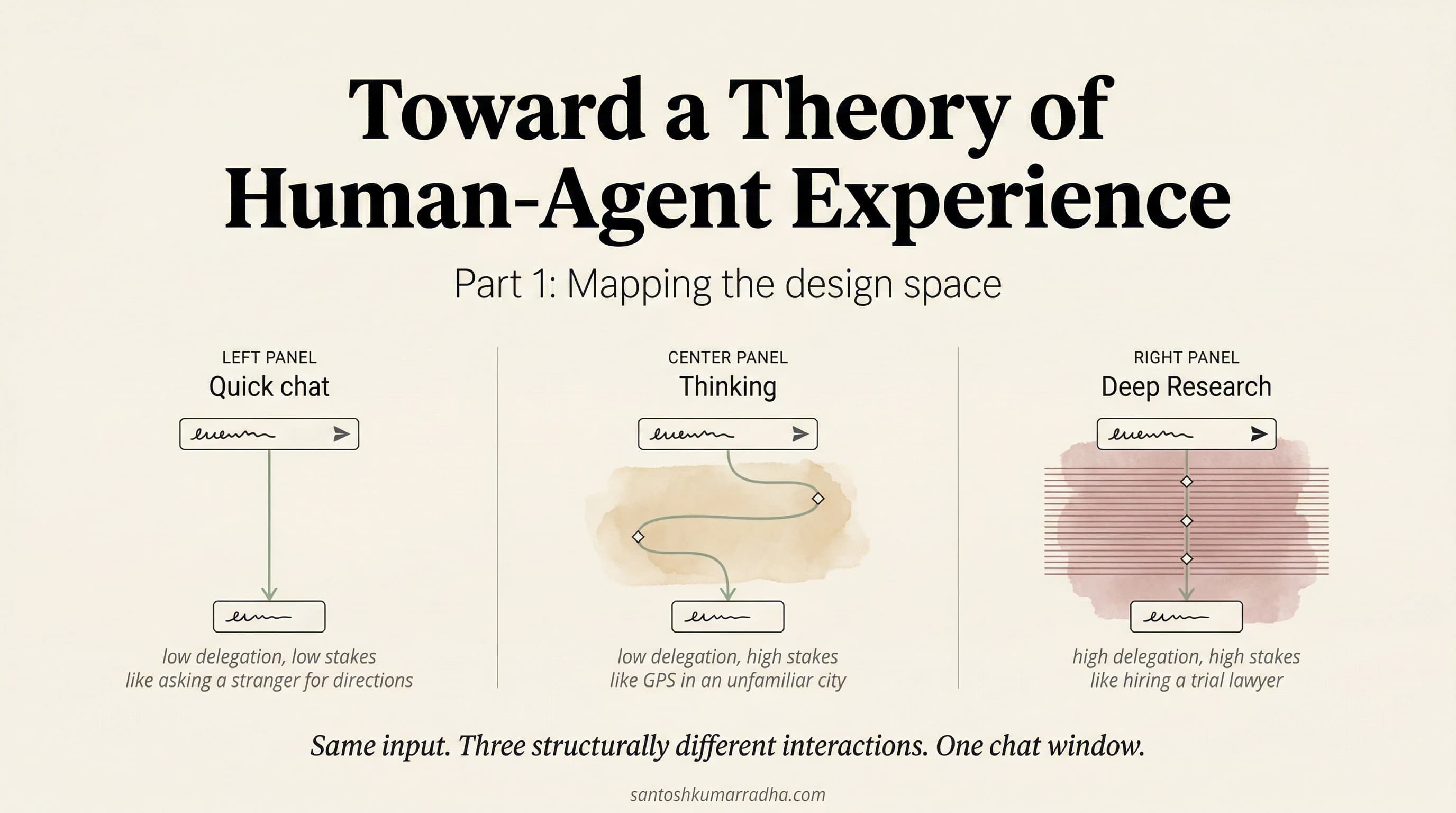
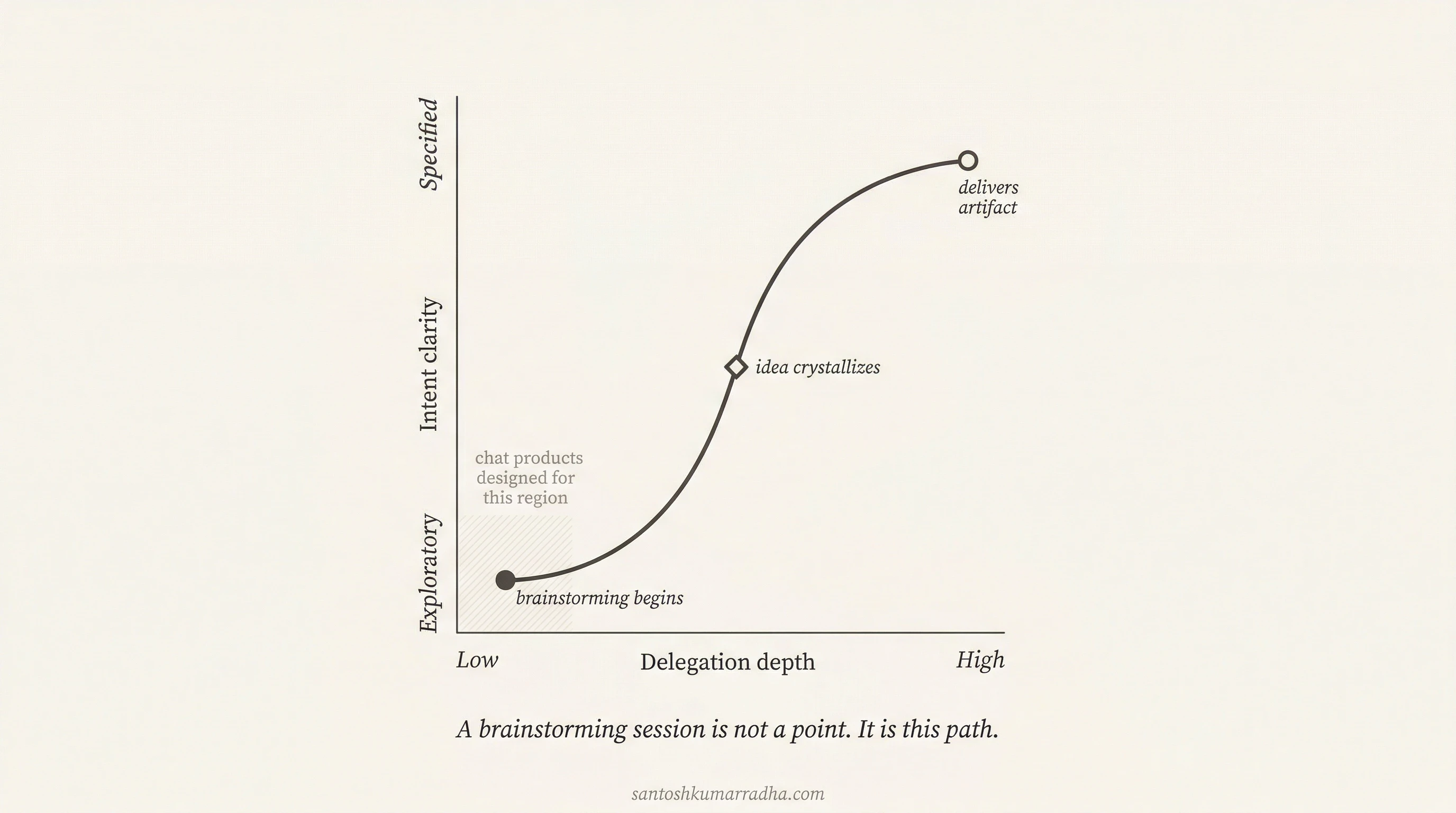
In the original four dimensions, the answer is clearly the latter. A brainstorming session starts with exploratory intent and low trust, crystallizes into a directed task as the human recognizes what they want, produces an artifact, and concludes. That is not a point; it is movement through the space, and the movement is the interaction. A product, by extension, is not a single point but a region, a volume of the space it is designed to support well. Current chat-based AI products occupy a relatively thin slice of the space (low-to-medium delegation, discrete tasks, low stakes), and they break down outside that slice because their interface was designed for one region and stretched to cover territory it cannot serve.
The distinction has direct design consequences. If each engagement sits at a stable location in the space, you can map design patterns to regions and be confident that the pattern will hold for the duration of the interaction. Trajectories demand adaptive interfaces that sense where the user currently is and adjust in real time, a significantly harder design problem.
The natural move is to look for a different set of dimensions, a rotation of the original axes, in which engagements are approximately stationary. The candidates are properties that remain stable throughout an engagement: stakes (the consequence of failure, typically set at the outset), autonomy budget (how much latitude the human is willing to grant), relationship duration (whether this is a one-off task or a persistent partnership), and domain complexity (how much context is needed to act well). In these dimensions, an engagement does sit closer to a fixed point, because these properties do not change as the interaction progresses.
But these invariant dimensions achieve stability at the cost of something essential: they describe the character of an engagement without specifying its demands. Knowing that an interaction is high-stakes and high-autonomy tells you the engagement is important and difficult, but it does not tell you how the product should be designed around it, whether it needs a briefing interface or a dashboard, whether oversight should be continuous or gated, whether the onboarding should take five seconds or five days, or how the system should handle the moment something goes wrong. These are the questions that determine the shape of the product itself, and the dimensions that answer them are precisely the ones that move during an engagement, which is why they produce trajectories rather than points.
The real question, then, is not whether to choose between stable dimensions and design-relevant ones, but whether a set of dimensions exists that is both: stable enough that an engagement approximates a point, and concrete enough to determine how the product around that engagement should be designed. That question leads naturally to compression, to asking whether the original dimensions contain redundancy that, once removed, yields a smaller set with both properties.
Compression
The question is which dimensions move together closely enough to be two expressions of a single underlying property.
Intent clarity and trust, examined together, reveal a deep entanglement. When intent is exploratory and the human does not know what they want, they remain tightly coupled to the AI regardless of how much they trust it, because the value of the interaction lies in the real-time exchange. When intent is fully specified and trust is high, the human delegates entirely and disengages until delivery. What these two dimensions independently describe turns out to be a single spectrum: delegation depth, the distance between the human's direct control and the point at which the AI operates. Low delegation depth means the human is in the loop at every step, co-creating in real time. High delegation depth means the human has handed off the work and may not engage again until the output arrives.
A similar compression applies to temporal structure and output nature. Artifacts tend toward episodic production cycles, state changes toward sustained background operation, and discrete actions toward burst interactions. The underlying variable is engagement continuity: whether the interaction is a bounded event with a clear endpoint or an open-ended process with no planned termination.
Two dimensions is elegant, and engagements in this compressed space do sit closer to stable points. But the compression goes too far. Stakes have disappeared entirely, and without them, a trivial task ("help me pick a restaurant") and a consequential one ("help me choose a cancer treatment plan") occupy the same coordinates despite demanding radically different design responses. Two dimensions is under-determined.

What remains, after compression removes the redundancy, is three.
Three dimensions
Delegation depth is the first. It captures how much autonomous judgment the human grants the AI, ranging from tightly-coupled co-creation where the human steers in real time, to full delegation where the human may not see the output for days. This single spectrum compresses what were originally separate properties of intent clarity, trust, and attention into one variable, and it directly determines how the product handles supervision: whether the human co-creates, reviews at checkpoints, or receives a finished deliverable.
Consequentiality, weighted by reversibility, is the second. It captures what is at stake if the AI gets it wrong, measured not by magnitude alone but by how easily the error can be undone. A wrong restaurant recommendation and a wrong legal filing may both be errors, but one you correct by choosing a different restaurant and the other reshapes a binding agreement. This dimension determines how the product handles safety: what requires confirmation, what demands evidence before action, where the undo boundary sits, and how much friction the interface should deliberately introduce to protect the user from the consequences of misplaced trust. Consequentiality may need further refinement; emotional harm and financial harm at the same severity level appear to demand different design responses, possibly because they differ in reversibility but possibly for deeper reasons not yet fully understood.
Commitment horizon is the third. It captures how far into the future the engagement extends, from an immediate single exchange through a bounded project with a clear endpoint to an open-ended relationship with no planned termination. This dimension determines how the product handles continuity: whether it needs persistent memory across sessions, whether trust should evolve over time, whether the terms of the relationship (how much autonomy the AI has, what it may and may not do) need to be renegotiable as circumstances change. Of the three dimensions, this one carries the least certainty; it may turn out to be a property of the task rather than a true independent axis of the interaction space. It is retained here because it governs product design decisions, particularly around memory, adaptation, and trust calibration, that the other two dimensions do not predict.
These three are not necessarily the final dimensions of this space. There may be rotations that reveal a more natural basis, axes that better carve the space at its joints. What matters at this stage is that the framework is constructed through a process rigorous enough to be challenged, extended, or refined, rather than asserted as finished. The value of naming these dimensions is not that they are certainly correct but that they provide a shared vocabulary for a conversation that, until now, has had none.
A first map of the space
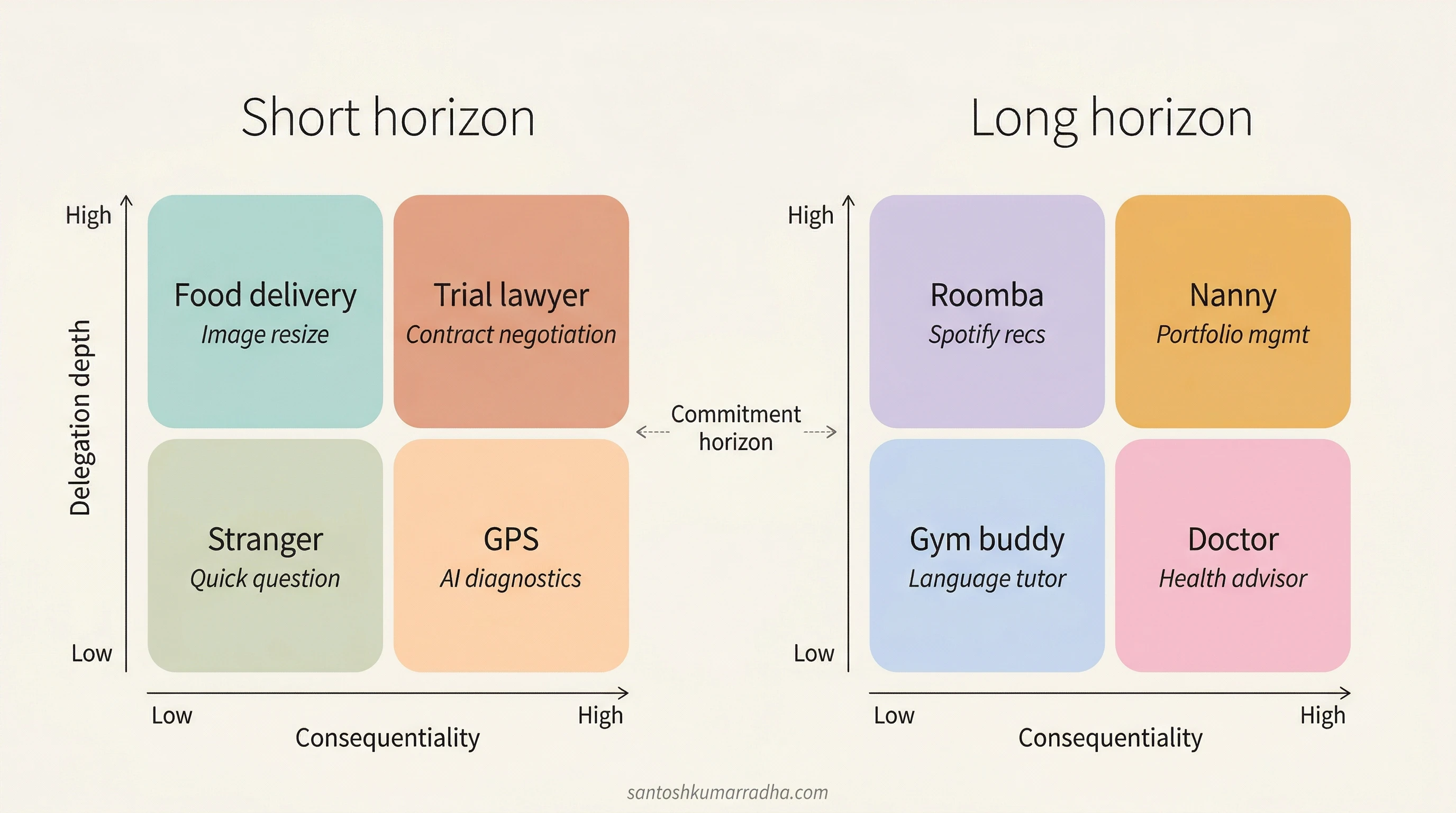
If each dimension is simplified to high and low, the three-dimensional space produces eight regions. Each region maps to a distinct human experience that immediately reveals the product design logic the region demands.
| Delegation | Consequentiality | Horizon | Familiar form | AI example | |
|---|---|---|---|---|---|
| 1 | Low | Low | Short | Asking a stranger for directions | "What is the capital of Mongolia?" |
| 2 | Low | Low | Long | A gym buddy | Language tutoring over months |
| 3 | Low | High | Short | GPS in an unfamiliar city | Doctor using AI diagnostic tool |
| 4 | Low | High | Long | Your doctor | AI health advisor over years |
| 5 | High | Low | Short | Food delivery | "Resize all these images to 800px" |
| 6 | High | Low | Long | A Roomba | Spotify recommendations, spam filter |
| 7 | High | High | Short | A trial lawyer | AI negotiating a contract |
| 8 | High | High | Long | A nanny | AI managing investment portfolio for years |
Region 1 is where roughly ninety percent of current AI interaction lives: low delegation, low stakes, a single exchange. The chat interface works here, and this is its native territory. The product design is minimal by necessity: text in, text out, no state, no memory, no confirmation workflow. The problem is not that the chat paradigm exists but that the industry has stretched it across all eight regions, applying the product logic of asking a stranger for directions to engagements that structurally resemble hiring a trial lawyer or entrusting a nanny with your children.
Region 2, the gym buddy, is where the commitment horizon begins to reshape the product. The individual session may feel conversational, but the value of the relationship lives in the continuity between sessions. The product needs persistent memory of progress, preferences, and patterns; it should surface trajectory (where you were, where you are, where you are heading) rather than treating each interaction as a fresh encounter. Most AI products today treat every conversation as Region 1 even when users are trying to build Region 2 relationships, and the resulting loss of memory and context is a direct consequence of not designing for this region of the space.
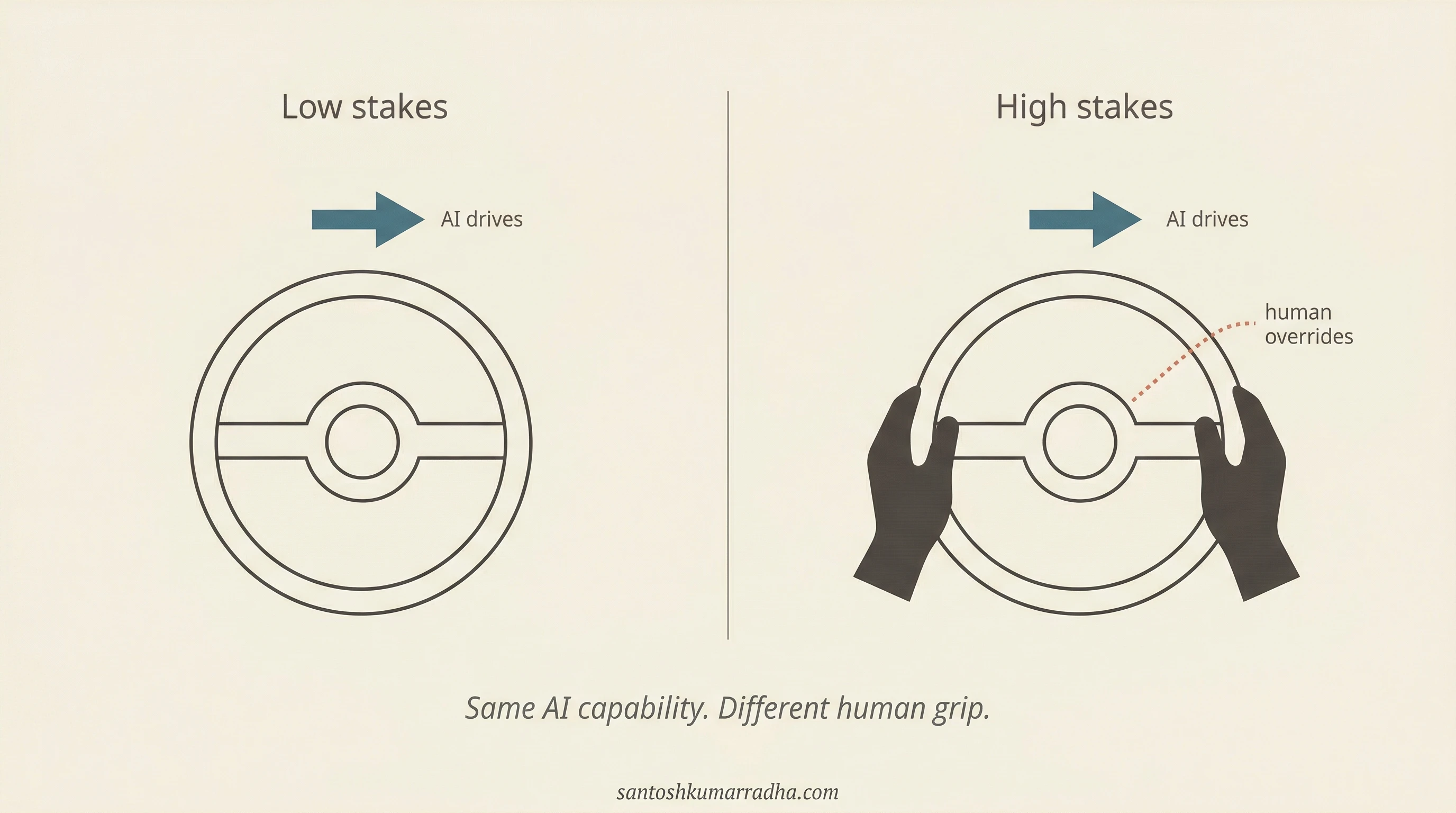
Region 3 reveals something counterintuitive. The metaphor is GPS in an unfamiliar city at night: the stakes are real, and even though the system may be more capable than the human at navigation, the human keeps their hands on the wheel and overrides when the suggested turn looks wrong. Everyone has had the moment where GPS says "turn right" and you can see it is a one-way street. You override, because you cannot afford not to. This is the principle that consequentiality suppresses delegation regardless of capability. Making the AI smarter does not move users out of this region; the product must be designed around the fact that the human will remain in the loop not because the AI is inadequate but because the cost of being wrong is too high. The interface presents evidence and recommendations, never decisions; it shows its work, cites its sources, and makes confidence levels visible, because the human needs to verify rapidly and the product must make that verification as efficient as possible.
Region 4, your doctor, extends this pattern across a long horizon. You see them regularly over years; they know your history, your risk tolerance, your values. The stakes remain high, and you never fully delegate, but the long relationship builds something that a new doctor cannot offer: accumulated context that makes each interaction more efficient and more informed. The product design challenge here is the richest in the low-delegation half of the space: deep longitudinal memory, decision-support interfaces that present options with tradeoffs rather than recommendations, and an audit trail of what was suggested, what was decided, and what happened. Trust in this region manifests as efficiency and comfort rather than increased autonomy; the product should become smoother over time, not more automatic.
Region 5 is food delivery. You delegate entirely, specify roughly what you want, and if the result is mediocre, you order again. The product design is deliberately frictionless: one-click commission with smart defaults, fast delivery, accept-or-redo as the entire interaction loop. No dashboards, no progress tracking, no approval workflows. This is where "vibe coding" and the "just generate it" culture lives, and the casual design is appropriate because the consequentiality permits it. But products that train users in Region 5 habits create problems when those users wander into Region 7 carrying the same expectations of effortless delegation into a space where the stakes no longer forgive mistakes.
Region 6 is a Roomba. You set it up once, it runs autonomously, and after six months you forget it exists, which is the highest compliment you can pay it. The product is invisible by default: configuration over conversation, interruptions only for genuine anomalies, and periodic subtle proof of value (the way Spotify Wrapped justifies a year of silent curation). The key metric is how rarely the user thinks about the system; attention required is a design failure, not engagement.
But Region 6 is also where the framework encounters a genuine limitation worth naming. Individually low-stakes decisions, accumulated over years, can produce high-stakes outcomes. A news feed algorithm making trivial curation decisions for a decade can reshape someone's worldview. The consequentiality axis as constructed measures per-decision stakes, not cumulative impact, and this means that Region 6 and Region 8 may be less distinct than the map suggests. Long-horizon, high-delegation interactions may always drift toward high consequentiality over time, regardless of where any individual decision sits on the scale.
Region 7 is a trial lawyer. You delegate enormous judgment: they speak for you, make real-time strategic decisions, and react to developments you did not anticipate. The stakes are high, but the engagement has a clear endpoint. The product design demands heavy upfront scoping (what the AI may and may not do autonomously), pre-authorization of boundaries, real-time status with interrupt capability, a full audit trail, and post-engagement review. The design challenge is making the necessary friction feel empowering rather than obstructive; confirmation steps and review checkpoints are not overhead but the core of the product's value, because they are what allows the human to delegate consequential judgment without losing control.
Region 8 is a nanny. The metaphor reveals the emotional and structural weight of this region immediately: you delegate enormous, consequential, daily judgment with no defined endpoint. You would never hire a nanny after a five-minute conversation. The onboarding is extensive, built around values alignment and trial periods. Once established, you do not micromanage (that defeats the purpose of high delegation), but you maintain oversight rituals: regular structured reviews, not because something went wrong, but as relationship maintenance. The product needs graduated autonomy that expands as trust is validated, the ability to renegotiate the delegation contract over time, and graceful degradation when something goes wrong, because in this region, a consequential mistake does not just produce a bad outcome; it threatens the relationship itself.
Almost no AI product has successfully designed for Region 8. It requires solving trust calibration, deep persistent memory, and the hardest open question in this space: how does a product recover from a consequential error in a way that preserves the relationship rather than destroying it? This is the frontier of Human-Agent Experience, where the most value will eventually be created and where the absence of a design theory will be felt most acutely.
What the map does not yet show
These eight regions are a first approximation, a coarse partition of a space that almost certainly has finer structure than three binary dimensions can capture. The boundaries between regions, where one kind of interaction begins to shade into another, are where the most demanding product design problems live, and some of the most interesting product decisions being made today are already responses to these boundary conditions, whether or not the teams making them have a shared language for describing what they are navigating.
Consider the design problem of extended reasoning, something users of ChatGPT and Claude now encounter regularly. A simple factual question and a problem that requires sustained analytical thinking enter through the same text field, but they occupy different regions of this space: the factual lookup is Region 1, while the complex reasoning task sits closer to Region 3, where the user needs to verify the logic and the cost of a flawed chain of reasoning is meaningfully higher. The question of when to engage deeper reasoning is, in this framework, a question of region detection: how does the product determine which region the user is in? ChatGPT's approach has been to remove the choice from the user entirely and let the model infer the region from the input itself. That is a specific product design stance, one that trades user control for reduced friction, and the framework suggests it works well when the boundary being crossed is between two low-consequentiality regions but becomes riskier as consequentiality increases.
A similar boundary surfaces in the distinction between answering a question and conducting research on the user's behalf, a tension visible in products like Perplexity and Gemini's Deep Research. "What is the best CRM for my startup?" could be a Region 1 interaction (give me a quick answer) or a Region 5 interaction (go investigate this thoroughly and bring me back a recommendation), and the user typing the query may not know which one they want until they see what comes back. The ambiguity is genuine, and these products have responded to it in structurally different ways. Gemini's Deep Research surfaces the AI's planned research trajectory before execution begins and lets the user edit it, a design pattern that introduces a scoping checkpoint borrowed from Region 7 (pre-authorization of boundaries) into an interaction that begins as Region 1. The product is acknowledging, through its design, that deep research is structurally a different kind of interaction from a quick answer, one that requires the human to confirm the direction before substantial autonomous work proceeds.
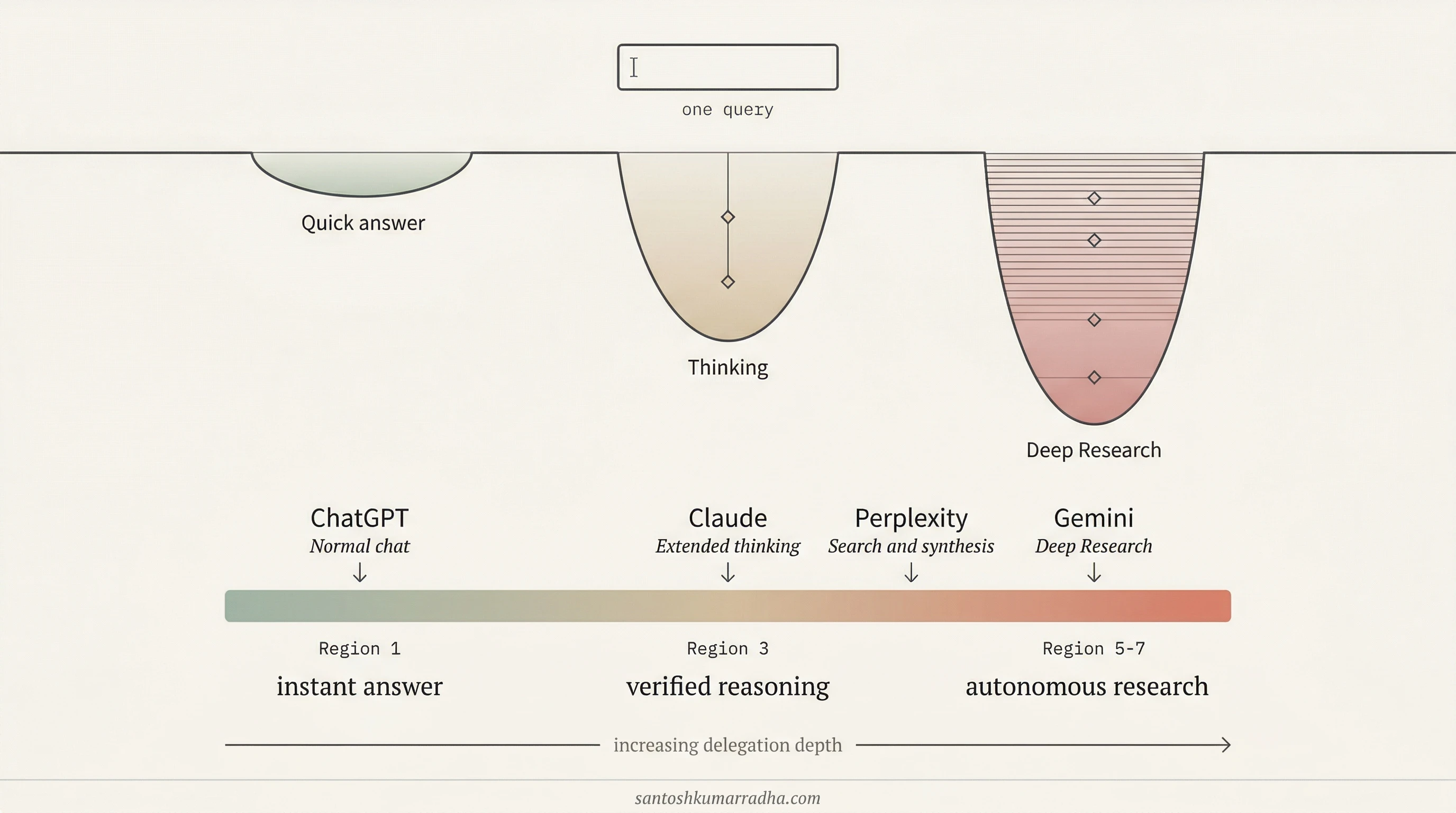
These are not isolated UX decisions. They are early, intuitive responses to the boundary problem that the framework makes explicit: the same input surface (a text field, a send button) serves interactions in fundamentally different regions of the space, and the product must either detect the region, ask the user to declare it, or design the transition between regions gracefully. Each approach has different tradeoffs, and the framework provides a vocabulary for reasoning about those tradeoffs rather than making them by instinct alone.
There is also the question of what the familiar forms obscure. Every entry in the map references a known human experience: strangers, gym buddies, doctors, lawyers, nannies. This is useful for building intuition about what each region demands, because the design logic of each familiar form has been refined over decades or centuries of human practice. But AI may eventually enable interaction patterns that have no human precedent, forms of collaboration between human and machine that do not resemble any prior delegation relationship. The familiar forms are bridges into this space, not permanent fixtures of it.
What this first map offers is something the field has lacked entirely: a shared vocabulary for talking about which kind of human-agent interaction a product is designed for, and a set of dimensions that explain why different regions of the space demand fundamentally different products rather than variations on a single interface. Whether these particular dimensions are the right ones, whether the space has additional axes not yet identified, and what happens at the boundaries between regions are questions that the rest of this series will explore.
The trust calibration and governance infrastructure for the high-delegation regions of this space is what we are building at agentfield.ai.

Santosh Kumar Radha
Physicist & CTO at agentfield.ai — building AI infrastructure for the future.